您好,根据您的描述,为您分点解答:
1.出现"_1",后缀名称是因为导入数据集时 已存在同名数据集,系统自动添加index 后缀 (即第三点中的 导入模式为“无”的情况)。
2.数据集的名称可以通俗理解为数据集的唯一标识,以便后续程序或人为判别和应用。
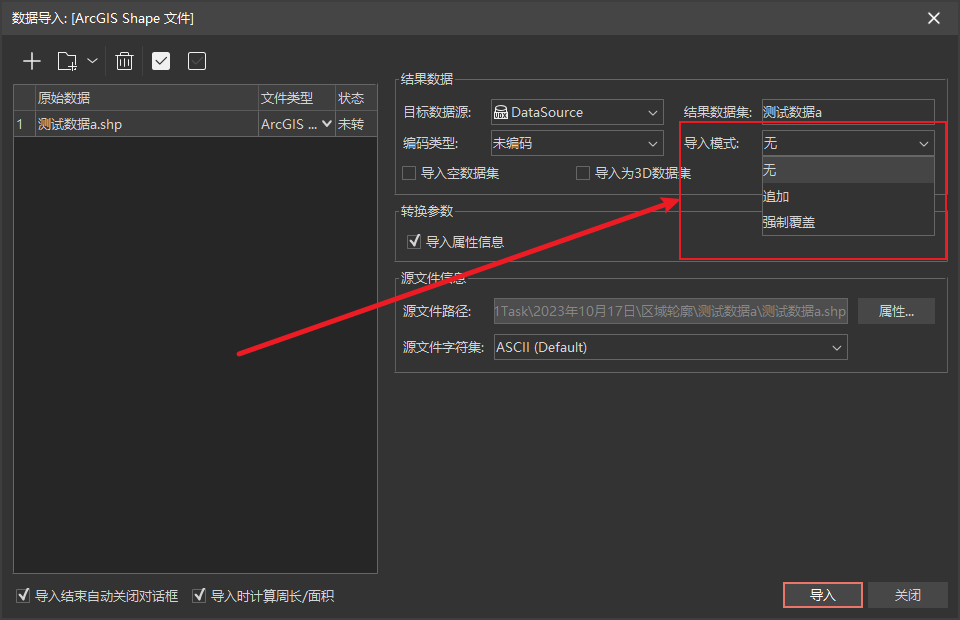
3.当“第一个数据集”存在时,再导入数据集需要使用同名可设置导入模式,分别为:
“无”:如导入的数据与已有数据集存在名称冲突,则导入的数据将自动修改名字并进行导入。
“追加”:如导入的数据与已有数据集存在名称冲突,则导入的数据追加到已有的同名数据集,追加的条件为同名的两个数据集的类型、结构完全一致。
“强制覆盖”:如导入的数据与已有数据集存在名称冲突,则导入的数据将强制覆盖已有的同名数据集。
根据您的情况,可以选择追加,或者强制覆盖。
4.数据集命名规则:
- 由汉字、字母、数字和下划线组成,但不能以数字、下划线开头。
- 长度不得为0,不得超过59个字符,即59个英文字母或者59个汉字。若数据集名称超过59个字符,超出部分会自动截断。
- 不能有非法字符,如空格、括号等。
- 不能与各个数据库的保留字段冲突。
桌面端,您可在如下截图处进行“导入模式”的设置
iObjects Java :您可使用API 判断名称是否可用
datasets.isAvailableDatasetName(name)
希望对您有所帮助!