您好,您这里在步骤2的使用时具体怎么使用的,是用的什么表达查询形式,如何超限的?正常使用应该不会超限的。
一般多对象进行空间查询时,通常是将这些对象放到/取到一个recordset里,如何设置在空间查询对象参数SpatialQueryObject上进行使用,参与查询的几何对象再多也不影响出现sql语句超限的问题,不太明白你参与查询的对象多为什么会导致sql语句这么长。
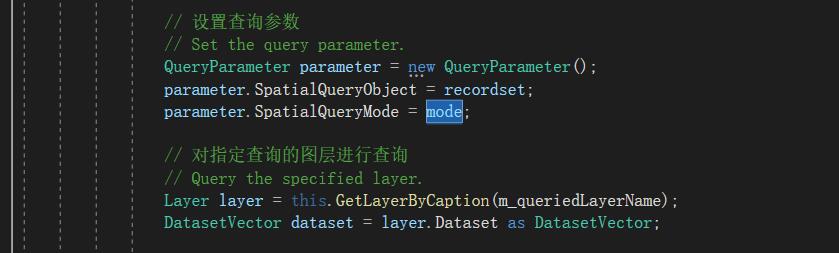
如果不太会使用空间查询的话,可以看一下空间查询的范例程序哦,安装目录\SampleCode\Data\SpatialQuery
希望可以帮助到您。